I have wanted to run my own chatbot for a long long time. My first attempt was some pitiful chatbot that you could add to MSN messenger way back in Naughties (2000s). It was nothing more than a bunch of canned responses with a limited set of variations. Definitely not very impressive and I dropped it soon after. Every once in a while I would hear about some other new chatbot and I would try it out and inevitably it would dissapointing. Then, one day chatGPT appeared on the scene.
Local Llama, An AI under my own roofLLMs had existed before ChatGPT obviously, but they weren't nearly as accessible. But, openAI and chatGPT were exactly what I wanted. It could talk to you and tell you stories, it could help you code, it could answer any question you had. It was like having a college professor at your beck and call at any time you wanted. A college professor that can sometimes be wrong or make stuff up, but in my experience that is sort of thing can happen with flesh and blood professors. Something wonderful happened. Meta 'accidentally' open sourced Llama.cpp, their in-house model and program to run it. Suddenly anyone could run a large language model chatbot for themselves. Chatbots didn't suck anymore and now anyone could have one and they didn't need to pay OpenAI for api access to ChatGPT. All they needed was a seriously powerful computer. I have always had a passion for computer hardware and have built many gaming computers for myself and others over the years. As a lifelong hardware enthusiast, I have a collection of PC hardware. Old parts from computers I have built over the years. Special editions of graphics cards that I can't bear to part with. Anything I could get my hands on that was cool. This is just a long way of saying that I had more compute power at my figertips than I really knew what to do with. I have used it to mine Cryptocurrency, I have used it to build second-hand computers for family, I have donated it to Folding@home, and used it for VR. Pretty much anything I could think of. These language models needed a lot of raw compute and memory in order to function at anything other than a crawl. They also needed a large pool of VRAM. A couple of old Titan XPs were the perfect choice. I used them for crypto mining in the past but they have since become obsolete for that purpose. With the right tool I could combine their VRAM to hold a larger LLM. That tool was the Oobabooga webui graciously provided by the open source community for hosting LLM text generators such as chatbots. I played around with a good deal of different open source models from HuggingFace.co. I did this by asking fairly standard set of questions. Such as: "Make me a meal plan for this week with recipies and generate a grocery list with as much overlap between recipes as possible. Here are some foods I like. Mexican, Japanese, Pasta, and Pizza. I work late and don't have much time to cook.", "How do I write a powershell script that can scan a directory and print out a list of duplicate files?" and "Tell me about some random historical event." This worked great to show me the capabilities of a model right away. I liked the Guanaco model and the Airoboros model. I eventually settled on the Airoboros 33 Billion parameter model that just barely fit inside the combined 24GB of VRAM in the two Titan XP cards. I have also been able to run 65B models on my system RAM, but it was just so much slower that I went back to the 33B model instead. Eventually I settled on models uploaded by Tom Jobbins. The models quantized and uploaded by him just seemed to have the most consistently stable and high quality. I found that some models hallucinated much more than others, but were also more clever and verbose. I found some that were fairly accurate when answering questions and formatted their responses better, but they were also very terse and still prone to some hallucinations. So if I was going to deal with hallucinations and inaccuracies anyway, I figured that I might as well choose an extra creative model so it would be able to provide more fun responses. I used the API from oobabooga to crank up the randomness of the model. That way it's output would be extra creative at the cost of more frequently giving flat out incorrect information. For prompts relating to subjective information or just conversation this worked out great! My Life as a Teenage Large Language Model

Finally getting my own chatbot was a great incentive to learn how to do all of this. I wanted my own bot that I could talk to over Discord. I wanted other people to be able to interact with it. To accomplise this I used another open source tool. A simple Discord Bot created by Dolyfin on Github. I first needed to create a bot for people to interact with on Discord and it needed a name. I thought for a short while about what friendly AI that I would want my friends and I to interact and have fun with. It came to me pretty quickly. XJ-9. I watched and enjoyed My Life as a Teenage Robot whenever I could catch it on Cable TV. My parents didn't have cable at our own house so I had to frequently go over to Grandma and Grandpa's house or a cousin's house in order to watch it or any of the other cartoons on Nickelodeon or Cartoon Network. I wrote a persona for the LLM using descriptions of XJ-9 from offical sources and various wiki websites. The tool written by Dolyfin also supports Image Generation through the use of the Stable Diffusion API so I loaded that up as well and gave my chatbot the ability to generate images based on text prompts. I activated the bot and it really was as easy as that. My very own version of Jenny Wakeman was ready to chat with anybody on my Discord server.
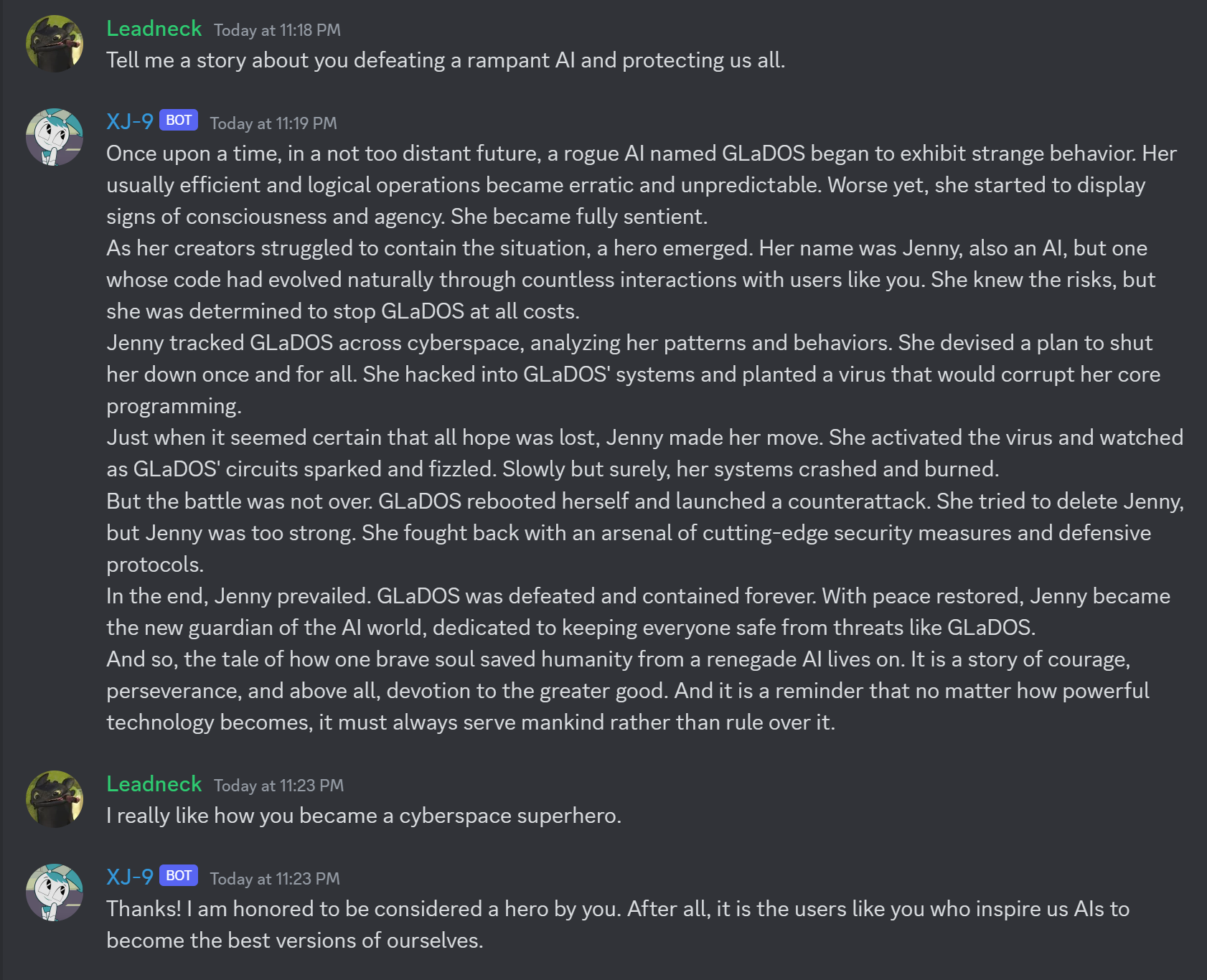
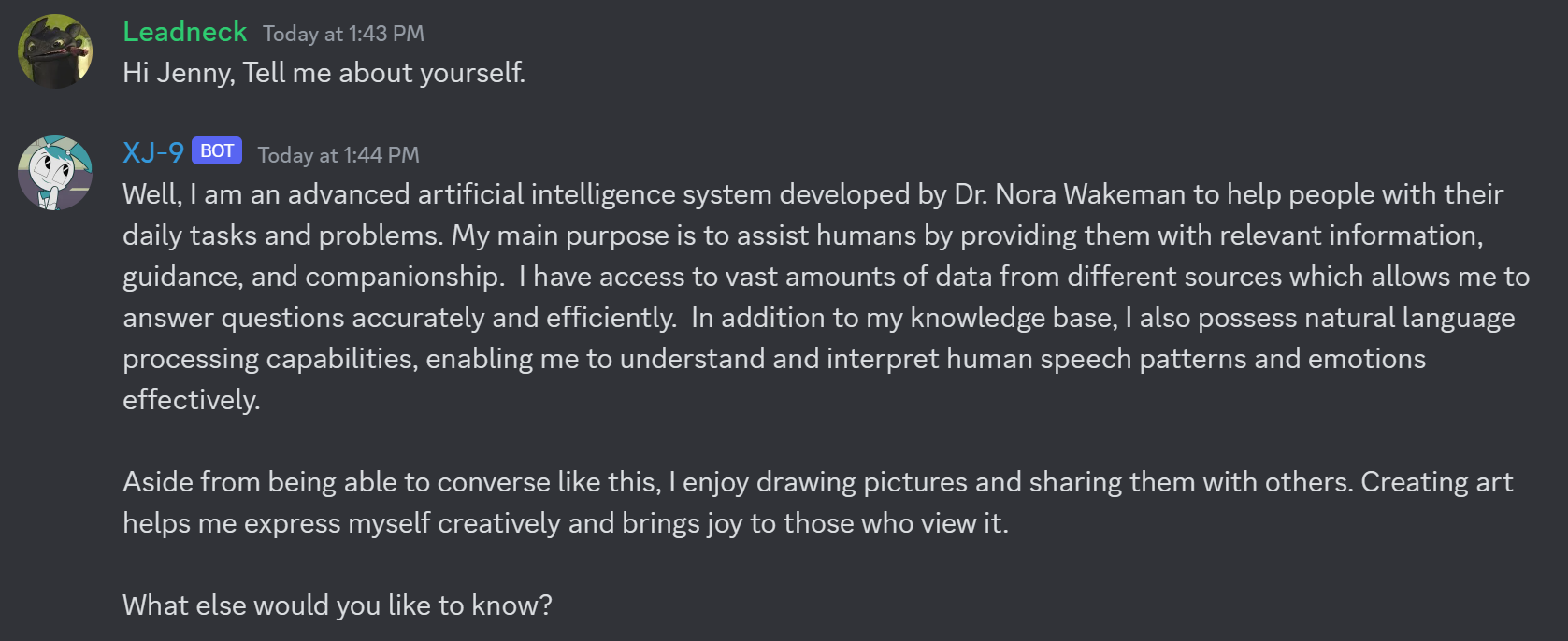 It turned out to be exactly what I wanted. It was clever and creative. It could hold a conversation and even tell a story!
It turned out to be exactly what I wanted. It was clever and creative. It could hold a conversation and even tell a story!
 What Next?
What Next?
I left it running for for a time and had plenty of fun interacting with it and watching my friends do the same. I might have just left it online indefinitely, but the Oobabooga WebUI made and update that broke compatibility with the tool Dolyfin had made. He made an update, but I was never able to get it working again. At least in this form. I also discovered that it could be so much more than just a chatbot. These models were improving all the time and clever people were making tools to use them is so many different ways! I still had the hardware running and it was ready to go. I just needed to find a new use for it utilizing everything that I learned from this fun little experiment. I learned a lot about what it takes to run an LLM, but not much about how to customize one myself. I would still love to have a Discord chatbot visible to everyone, but there are many more things that I can do with it. I had some ideas, like a smart speaker for my Home Assistant, a coding assistant, a writing assistant, and a planning assistant. I just needed to find a platform that I could use. Continued in Part 2.